一、说文解字,学习一下Collation的字面意思:排序。 (https://en.wikipedia.org/wiki/Collation)
二、SQL中的Collation,描述了如何对查询出来的数据进行比较和排序,本质是定义了两个cell的数据进行比较的时候的compare算法。
三、特别说明几个SQL Collation常见词汇:
1. ci: case ignore/insensitive,比较的时候不区分大小写
2. mb4: multi-bytes-4,4字节字符集
3. utf8mb4_unicode_ci: utf8mb4表示编码规则为支持4个字节字符的utf8,unicode表示采用UNICODE编码(UNICODE编码将几乎地球上所有字符都赋予一个数字编号)。
四、感性例子:a和b的collation都是utf8-general-ci,不区分大小写,所以where可以查询出所有符合条件的大写、小写字符串。
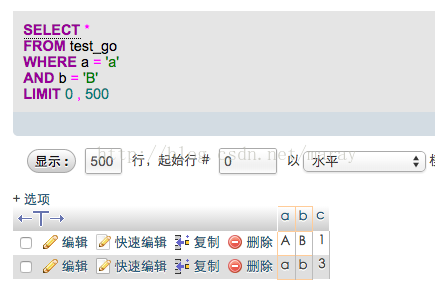
深入一些的思考(这时候就绕不开字符集问题了,如果你要实现一个数据库,实现compare算法,这个必须面对):
一、UTF8,UNICODE,GB2312这些,都是什么鬼?
地球上有这样一群猴子,他们觉得必须给全世界乱七八糟的文字编一个字典,每一页上写一个“字”。这本字典编成后,世界上每个字都有了一个唯一的页码。这个页码,就是这个字的UNI-CODE。UNI-CODE,就是UNI(统一)-CODE(编码)的意思。有UNICODE的时候,这群猴子还没发明计算机。所以,UNICODE和计算机无关。
后来,猴子进化成了人,发明了计算机,他们想在计算机上用UNICODE。最简单,最直观的方式就是把字典页码作为一个数字记录到计算机里面,第10356页,放到计算机里面就是数字10356(0x2874),这就是UCS-2编码了。地球上的文字如果少于65536个,那么用UCS-2可以全部都表示出来。地球上的文字如果多余65536个呢?那就必须用UCS-4编码了,4个字节搞定全世界。特别注意,我用了一个词汇:编码。UNICODE到UCS-2,是一一相等映射的,即便如此简单,也是一种编码过程。
可惜,早期的人类缺乏先见之明,只考虑了ASCII码。并且,他们还发明了UNIX操作系统,在UNIX下相当多得工具中,单字节的0被当做了一种非常特殊的字符:字符串终结符。这时候问题就来了,如果采用UCS-2或者UCS-4,这些工具会统统完蛋。
为了解决这个问题,就需要采用一些编码技术,把字典编号(UNICODE)映射到一个不包含0byte的编码空间中,绕开0这个东西,目标编码,就是UTF8。如下图:
U-00000000 - U-0000007F: 0xxxxxxx
U-00000080 - U-000007FF: 110xxxxx 10xxxxxx
U-00000800 - U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
U-00010000 - U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
U-00200000 - U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 - U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
左边是UNICODE空间,右边是UTF8空间。所以,UTF8,只是UNICODE在计算机里的一种表示方式而已,它的诞生,源于:1,规避单字节0内容 2,高效编码(相对于UCS-2, UCS-4)。
Note:
1.UCS代表Universal Character Set通用字符集
2.UTF代表UCS Transformation Format
一个不错的参考文献:http://zhidao.baidu.com/question/2692826.html
那么,什么是GB2312呢?它是和UNICODE地位相等的。也就是说,它和UTF8、UNICODE没有任何关系。他是另一本字典,主要针对中文字符。
二、utf8mb4_unicode_ci又是几个意思呢?它跟utf8mb4_generic_ci有啥区别?
按理说出现了utf8的地方,就没必要再出现unicode了,因为utf8肯定是用于表示unicode的。所以,不用纠结了,上面俩东西,就是人造出来的,用来表示某种区别(编程做变量命名的人肯定有这种经验,单词只是用来表示某种意思的,并不一定精确)。区别是啥呢?generic就是用古板的unicode数字比较,性能高。unicode方式,能处理一些“变体”的比较,例如,在德语和一些其它语言中‘ß’等于‘ss’。参考这篇文章,讲得很好:http://www.chinaz.com/program/2010/0225/107151.shtml