为什么需要 CGroup
Linux Namespace 为容器(进程)提供了环境上的隔离,它的行为类似 chroot 这个命令,将某个用户jail 到一个特定的环境下,与外界隔离。但是在之前介绍 Namespace 的文章中我们也提到过,虽然 Namespace 提供的隔离机制有很多,但实际上我们操作的一些资源仍然是全局的,并且基本上是没有什么限制的,如:内存,CPU,硬盘等。一些在已经「隔离」了的进程中做的操作还是会影响到其他进程的。
所以,Linux 在内核中以文件系统的形式为我们实现了一种资源隔离的机制:Linux CGroup,位于 /sys/fs/cgroup 目录 。它用来限制,控制一个进程群组的资源。工作方式类似于:先对计算机的某个资源设置了一些限制规则,如只能使用 CPU 的20%。然后,如果我们想一些进程去遵守这个使用 CPU 资源的限制的话,就将它加入到这个规则所绑定的进程组中,之后,相应的限制就会对其生效。
总的来说,使用 CGroup,可以以控制组为单位,对其使用的操作系统的资源做更精细的控制。
使用 CGroup
其实 CGroup 说到底就是内核实现的一个资源隔离的功能,既然是一个功能,那直接去使用它将会有一个更加直观的了解:
先来看下 cgroup 的文件系统下都提供了对那些资源的隔离:
xr@xr-lab:/sys/fs/cgroup$ ll
total 0
drwxr-xr-x 15 root root 380 10月 24 14:35 ./
drwxr-xr-x 11 root root 0 10月 24 19:33 ../
dr-xr-xr-x 4 root root 0 10月 24 19:33 blkio/
lrwxrwxrwx 1 root root 11 10月 24 14:35 cpu -> cpu,cpuacct/
lrwxrwxrwx 1 root root 11 10月 24 14:35 cpuacct -> cpu,cpuacct/
dr-xr-xr-x 5 root root 0 10月 24 19:39 cpu,cpuacct/
dr-xr-xr-x 2 root root 0 10月 24 19:33 cpuset/
dr-xr-xr-x 4 root root 0 10月 24 19:33 devices/
dr-xr-xr-x 2 root root 0 10月 24 19:33 freezer/
dr-xr-xr-x 2 root root 0 10月 24 19:33 hugetlb/
dr-xr-xr-x 4 root root 0 10月 24 19:33 memory/
lrwxrwxrwx 1 root root 16 10月 24 14:35 net_cls -> net_cls,net_prio/
dr-xr-xr-x 2 root root 0 10月 24 19:33 net_cls,net_prio/
lrwxrwxrwx 1 root root 16 10月 24 14:35 net_prio -> net_cls,net_prio/
dr-xr-xr-x 2 root root 0 10月 24 19:33 perf_event/
dr-xr-xr-x 4 root root 0 10月 24 19:33 pids/
dr-xr-xr-x 2 root root 0 10月 24 19:33 rdma/
dr-xr-xr-x 5 root root 0 10月 24 19:33 systemd/
dr-xr-xr-x 5 root root 0 10月 24 19:33 unified/其中 cpu 和 memory 我们都是比较熟悉的,而 blkio 代表了用于 I/O 的块设备,姑且可以将它当做是硬盘资源吧。假设我们现在有一个核心逻辑为「死循环」的程序:
// 该例子参考了陈皓老师的博客:https://coolshell.cn/articles/17049.html,欢迎大家去原文观看
int main(void)
{
int i = 0;
for(;;) i++;
return 0;
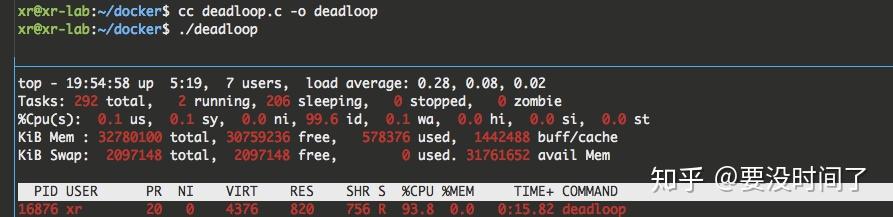
}启动了该程序后,可以通过 top命令看到其 CPU 占用率已经到达了100%
现在,我们准备继续改造一下这个小程序:
- 父进程启动后且创建子进程之前在 /sys/fs/cgroup/cpu 目录下再新建一个目录,作为一个我们自定义的进程组。并且对这个进程组使用的 CPU 资源写入一个限制规则:只能使用 CPU 的50%
- 创建一个子进程并将其加入到我们已经创建好的进程组中,然后执行「死循环」逻辑
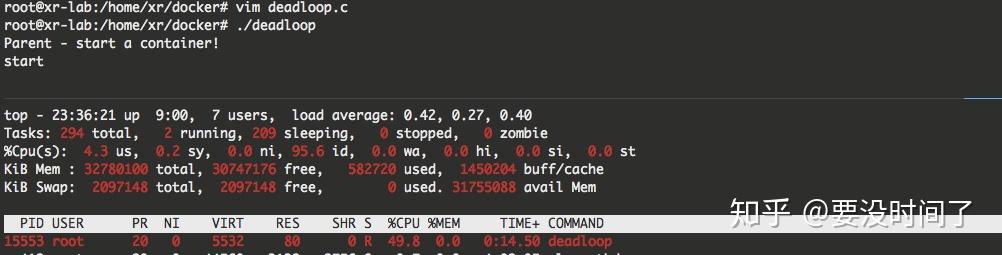
#include 在上面的例子中,我使用了一个 pipe 做父子进程间的同步,确保父进程把子进程 id 写入到名为 deadloop 的进程组之后再唤醒子进程执行死循环的逻辑。编译执行后,可以通过 top 命令看到,子进程的 CPU 利用率已经被限制到了50%。
除了对 CPU 限制之外,对 MEM,硬盘容量都可以做限制,甚至对某个块设备的读写速率也是可以限制的。
一些重要的概念
子系统
在 CGroup 中,有很多子系统。一个子系统就代表一个资源控制器。sys/fs/cgroup 目录下的项目就是目前操作系统提供的全部子系统。
控制组 (Control Group)
一个控制组包含多个进程,而资源的限制也是定义在控制组上的。若一个进程加入到某一个控制组,则自动会受到定义在这个控制组上面的限制规则的影响。
层级
一个子系统下面的控制组,可以进行嵌套,最终形成一个树形的结构。子节点控制组会继承父节点控制组上对于资源的限制规则。若在子节点的控制组重定义了和父节点中相同资源的规则,则会发生覆盖(子覆盖父)
总结
在 Docker 中,其实也是通过 CGroup 来实现对容器使用资源的限制的。如果你在 k8s 的环境下工作过,可能会对资源的「 Request」 和「Limit」 的概念比较熟悉。这是 k8s 给用户提供的一个可以指定容器使用资源限制的一个入口。最终到了操作系统这里,还是通过 CGroup 实现的。